MSE vs MAE in Linear Regression
In the case of MSE (Mean Square Error)
- Error (predicted value — true value) follows the standard normal distribution [Mean 0 and Variance 1]
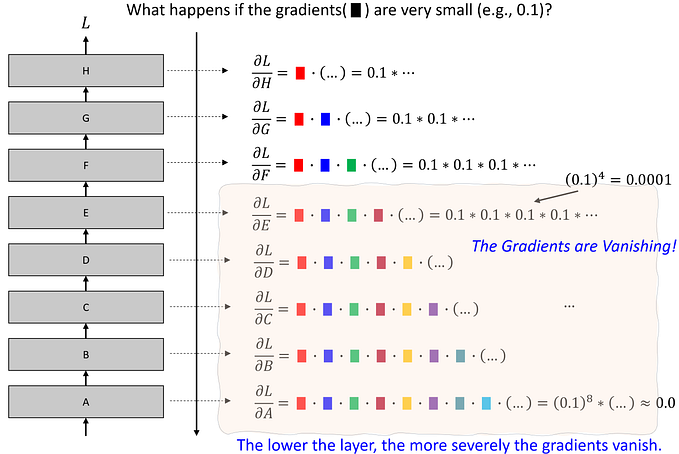
As we train linear regression using MSE, it pushes the total error towards zero. Due to this,
- The regression line models the mean of the prediction.
- The algorithm becomes sensitive toward outliers.
Let’s see the implementation of Linear Regression with MSE
import matplotlib.pyplot as pltimport numpy as npimport torchimport torch.nn as nnfrom torch.autograd import Variablefrom sklearn.datasets import make_regression
x_dim = 1y_dim = 1seed = 42np.random.seed(seed)torch.manual_seed(seed)device = 'cuda' if torch.cuda.is_available() else 'cpu'
# Datasetx_values, y_values = make_regression(n_samples=50, n_features=x_dim, noise=50, random_state=seed)
# Manually adding the outlier pointx_values[0] = 2y_values[0] = 500
x_train = np.array(x_values, dtype=np.float32)x_train = x_train.reshape(-1, x_dim)y_train = np.array(y_values, dtype=np.float32)y_train = y_train.reshape(-1, y_dim)plt.plot(x_train, y_train, 'go', alpha=0.5)plt.show()

Linear Regression Model
class LR(nn.Module):
def __init__(self, x_dim, y_dim=1):
super(LR, self).__init__()
self.linear = nn.Linear(x_dim, y_dim)
def forward(self, x):
return self.linear(x)Model Training
learning_rate = 0.0002
num_epochs = 20000mse_model = LR(x_dim, y_dim)mse_model = mse_model.to(device)criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(mse_model.parameters(), lr=learning_rate)total_loss = []
for _ in range(num_epochs):inputs = torch.from_numpy(x_train).to(device)
labels = torch.from_numpy(y_train).to(device)optimizer.zero_grad()outputs = mse_model(inputs)loss = criterion(outputs, labels)
loss.backward()
optimizer.step()total_loss.append(loss.item())plt.plot(total_loss)
plt.show()

Model Evaluation + Error Term
with torch.no_grad():
inputs = torch.from_numpy(x_train).to(device)
predicted = mse_model(inputs).cpu().data.numpy()error = (predicted - y_train).reshape(-1)
pos_count = np.sum(error >= 0)
neg_count = np.sum(error < 0)print(f"Number of positive error {pos_count}")
print(f"Number of negative error {neg_count}")
print(f"Total Error {np.sum(error)}")
Output

Takeaway: Theoretically, we must have a total error value of 0. However, we are getting it as -1.86 [Closer to 0] which shows that the learned weights are not optimal yet.
In the case of MAE (Mean Absolute Error)
- Error (predicted value — true value) may no longer follow the standard normal distribution.
- The number of data points with positive error is the same as the number of data points with negative error.
Let’s take a very simple example to understand 2nd point.
Loss Formulation is:

where

When we take the derivation of L with respect to w, we get

To find the best value of w that minimize this loss function, we have to

where


For this
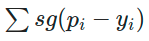
expression to be 0, we much have an equal number of positive and negative errors.
Mathematical proof over here: https://gennadylaptev.medium.com/median-and-mae-3e85f92df2d7
As we train linear regression using MAE, it pushes toward an equal number of positive errors and negative errors. Due to this,
- The regression line models the median of the prediction.
- The algorithm becomes robust toward outliers.
Model Training
learning_rate = 0.015
num_epochs = 20000mae_model = LR(x_dim, y_dim)criterion = torch.nn.L1Loss()
optimizer = torch.optim.SGD(mae_model.parameters(), lr=learning_rate)total_loss = []
for _ in range(num_epochs):inputs = torch.from_numpy(x_train).to(device)
labels = torch.from_numpy(y_train).to(device)optimizer.zero_grad()outputs = mae_model(inputs)loss = criterion(outputs, labels)
loss.backward()
optimizer.step()total_loss.append(loss.item())plt.plot(total_loss)
plt.show()

Model Evaluation + Error Term
with torch.no_grad():
inputs = torch.from_numpy(x_train).to(device)
predicted = mae_model(inputs).cpu().data.numpy()error = (predicted - y_train).reshape(-1)
pos_count = np.sum(error >= 0)
neg_count = np.sum(error < 0)print(f"Number of positive error {pos_count}")
print(f"Number of negative error {neg_count}")
print(f"Total Error {np.sum(error)}")
Output

Takeaway: We get an equal number of positive and negative errors. The total error is too far away from 0.
Conclusion:
Linear Regression with MSE gives the mean predictor whereas Linear Regression with MAE gives the median predictor.